
Lukas Tennie - Unsplashed
Similar-looking search systems can behave very differently in production. Take two search systems. Both have an index of around 100k documents.
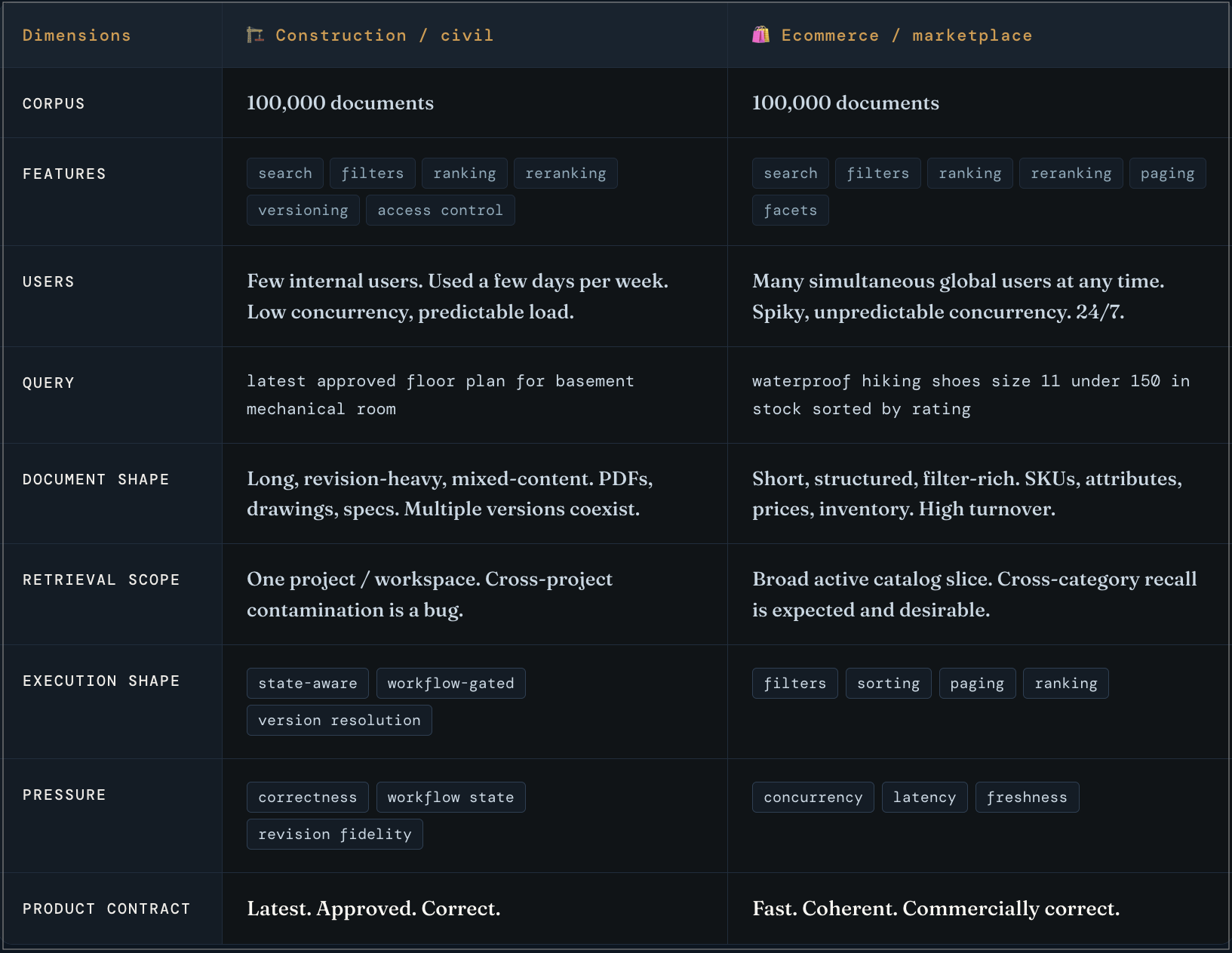
One is a search system for construction and civil engineering documents. Queries look like latest approved floor plan for basement mechanical room.
Another is an ecommerce search system. Queries look like waterproof hiking shoes size 11 under 150, in stock, sorted by rating.
Both support hybrid search, filters, reranking - so, same broad feature set. But they behave differently in the production. Document count is often considered an useful proxy for scale, but that explains only part of the system's behavior. The difference comes from the interaction of the six factors in the search engine: query shape, document shape, retrieval scope, execution shape, operating pressure, and product contract.
Search systems are more than retrieval
At the interface boundary, search can look simple:
query -> index lookup -> ranked results
Once the system carries real product responsibility, retrieval has to work together with filters, counts, sorting, paging, reranking, freshness, access control, and business rules.
The hard part is in those interactions. Each mechanism can change the behavior of the others, while users experience the results as one system.
Query shape, document shape, and retrieval scope
Query shape.
Queries do different jobs, and they vary on the levels of complexity:
- state-aware lookup, e.g.
latest approved floor plan for basement mechanical room - constraint-heavy retrieval, e.g.
waterproof hiking shoes size 11 under 100, in stock - known-item lookup, e.g.
Nike Pegasus 41 - scoped similarity search, e.g.
find similar language across these custodians - comparison over a bounded set, e.g.
compare concrete curing requirements across these three revisions
These are different retrieval job. They drive different execution shape, and different forms of hardware pressures.
Document shape.
Short product records, long contracts, revision-heavy drawing packages, email threads, multilingual content, and mixed-content PDFs do not create the same retrieval problem. Document shape affects how content is structured, segmented, stored, and matched against the user query.
The retrieval unit (e.g. chunks, fields, etc.) often matters more than the document the document abstraction suggests. Teams often think they are debugging documents when they are really debugging retrieval units.
Retrieval scope.
The system rarely searches everything it stores. It searches the live slice for this request: one project, one tenant, one matter, one seller slice, a full catalog, a portfolio-wide index.
That scope defined the retrieval job. A narrow, well-structured scope can make a large stored collection cheap to search. A smaller collection with a broad or unstable live scope can be much harder to serve.
Execution shape
Execution shape is how the system turns that retrieval job into results.
Lexical, vector, and hybrid retrieval are only the headline labels. Production behavior usually depends on lower-level choices.
Execution shape also affects serving economics: a system that retrieves 100 candidates, filters early, and reranks once has a different cost curve from one that retrieves 1,000 candidates, filters late, and relies on downstream reranking or application logic.
Approximation.
Exact search and ANN change latency, recall, memory use, filtering behavior, and update cost. They also change what kinds of surprises the system produces under load.
Candidate generation.
A reranker only improves what it gets to see. If the right items never enter the candidate set, the reranker has nothing to rescue. Many ranking problems start as candidate-generation problems and only show up later as "relevance" complaints.
Filter timing.
Pre-search filtering defines eligibility before candidate generation. Post-search filtering trims what a broader search already surfaced. Those are not the same system. In vector and hybrid retrieval, that difference often decides recall, latency, and whether counts, hits, and ranking stay aligned.
Seams.
Responsibility is often split across retrieval, filtering, fusion, reranking, application logic, business rules, and sometimes a generative layer. Each boundary is another place where relevance shifts, latency accumulates, and debugging crosses ownership lines. When the same retrieval layer feeds RAG or multi-step agents, those shifts are carried forward into the answer layer.
Operating pressures and Product contract
Serving economics.
Two systems can support the same retrieval mode but have different cost curves because they keep different parts of the serving path hot. One may need large indexes, candidate sets, or reranking paths resident on serving nodes. Another may rely more on storage, caching, or downstream compute. Those choices shape what each query costs to serve before traffic pressure even arrives.
Hardware pressure.
CPU, RAM, storage, cache behavior, and headroom decide how much inefficiency the system can absorb before users notice.
Update pressure.
Static corpora, daily batch workloads, and continuously updated indexes are different systems. Refresh behavior, merge behavior, stale state, and indexing cost start to matter as soon as retrieval structures have to stay current.
Traffic pressure.
QPS and concurrency expose hidden cost fast. A system used by a few people can look fine with late filtering, over-retrieval, and expensive reranking. The same system under hundreds of concurrent users, while indexes are also updating, can become unstable quickly.
Product contract.
Low latency, stable paging, reliable counts, current state, explanation, auditability, and policy correctness are not the same kind of requirement, but they all define what "working" means. A system that is acceptable for internal search can be unusable for marketplace ranking or compliance review.
This is why teams report opposite experiences with superficially similar systems. They operating under different serving economics, different pressures, and different product contracts.
Where failures show up
Most failures collapse into three buckets:
- recall failure: the right thing never enters the candidate set
- scope failure: the system searches or returns the wrong slice
- ranking failure: the right candidates are present, but the ordering is weak or unstable
One more term belongs here:
- cracks: seams that become visible under pressure
Cracks show up when concurrent user queries are happening, simultaneously index is upating, counts diverge from matching hits, paging wobbles after reranking, lexical and vector paths disagree under filters, freshness diverges across paths, or one bad result requires tracing three different layers to explain.
Case in point: hybrid search
Hybrid search exposes these problems quickly because it combines more than one retrieval behavior inside one product surface.
The hybrid search is lexical + vector with optionally, an reranker.
In production, the system has to present retrieval, filters, aggregations, sorting, paging, reranking, freshness, explanation, and business rules as one coherent result model.
Each part pulls in a different directions. Filters want the right slice. Aggregations want counts over that slice. Sorting wants stable order. Paging wants page two to behave like page two. Reranking wants a rich candidate set. Vector retrieval wants semantic proximity. Lexical retrieval wants exact term sensitivity.
This is where systems start to wobble in visible ways: page one looks plausible, counts drift, filters expose disagreements between retrieval paths - lexical and vectors, and latency climbs as more work gets pushed into reranking or application logic. The same failure can also become an economics problem: larger candidate windows, more reranker calls, more hot index state, or more cache pressure may be needed just to preserve the same visible behavior.
In RAG systems, the hybrid retrieval inconsistencies propogate into context selection, grounding, and the final answer.
Three systems with similar corpus size
Construction and engineering search is typically revision-heavy and approval-sensitive.
latest approved floor plan for basement mechanical roomfire suppression specification for the east wing
The dominant pressure is workflow-state correctness. What cracks first is usually scope, revision, or state coherence, especially around words like latest and approved.
Ecommerce and marketplace search is typically filter-heavy, freshness-sensitive, and ranking-sensitive.
waterproof hiking shoes size 11 under 150, in stockespresso machine with grinder sorted by rating
The dominant pressure is keeping filters, ranking, paging, and current state coherent under interactive load. What cracks first is usually paging stability, facet coherence, freshness correctness, tail latency, or the cost of keeping enough candidates hot and rerankable. The result often looks plausible on page one and inconsistent by page two.
Legal, litigation, and compliance retrieval is typically metadata-heavy, scope-heavy, and explanation-sensitive.
emails discussing pricing strategy between January and Marchfind similar language across these custodians
The dominant pressure is defensibility under selective scope and permissions. What cracks first is usually scope correctness, family or thread coherence, or auditability. A system can look relevant and still be unusable if the scope is even slightly wrong.
Same corpus size. Different retrieval job. Different execution shape. Different serving economics. Different pressure. Different cracks.
The takeaway
Search gets hard when multiple parts of the system have to agree on one result set under real operating pressure. Concurrent search queries, hardware limits, evolving indexes, latency and freshness requirements, LLM serving dependencies, etc. all strain that agreement. The failures become visible when the system stops behaving like one coherent system.
Demos mislead for the same reason. Similar corpus sizes can produce very different systems, and the same architecture can feel acceptable in one product and broken in another. The cost curve can also be different: one system may need large indexes, candidate sets, or reranking paths to stay continuously hot at serving time, while another pushes more work into storage, caching, or downstream compute. Those are architecture decisions, not just infrastructure details.
The same is true for production AI. When retrieval stops behaving like one coherent system, the answer layer inherits the failure.
This is one reason we describe production AI systems as depending on a Retrieval Foundation.