
Suspension bridge cables close up (Nano Banana)
A search stack can keep returning plausible results long after its internal behavior has started to drift.
Latency is still acceptable. The common queries still look fine. No single component appears obviously broken. But small changes start producing larger effects than the team expects: a new filter removes an expected item, a policy condition changes which candidates survive, or widening the candidate set from 100 to 500 produces a quality jump that should not have come from a small tuning change.
That is usually how strain begins.
The stack still works, but keeping one coherent result now takes more effort than it used to. More cases need caveats. More fixes become case-specific. More quality depends on later-stage correction. The team still ships improvements, but it also spends more time preserving behavior that used to hold with less intervention.
The broader frame is in What Makes Search Hard: retrieval, filtering, ranking, serving economics, and product constraints have to behave like one result model under pressure. The next production question is what happens when that agreement gets harder to preserve.
The answer is not simply that relevance is getting worse. Some cracks still point to local cleanup or tuning. Others point to a broader shift in the operating regime. They also do not stay isolated for long: one weak layer can make another one look guilty, and a temporary fix in one place can hide strain somewhere else. Treating every recurring failure as generic relevance work is how teams spend months tuning the wrong layer.
The signal is strain, not failure
Strain does not require visible failure. It appears when the system still functions, but the work required to keep the result stable starts increasing. Queries behave broadly as expected, but more cases need caveats. Filters still narrow the result, but sometimes they distort candidate survival. Reranking still improves quality, but starts doing more recovery than refinement. One bad result is still explainable, but the explanation crosses more layers than before.
Operating pressure. Concurrent traffic, freshness requirements, and tighter latency targets change how much inefficiency the system can absorb.
Retrieval scope. Cross-workspace, cross-tenant, or cross-catalog retrieval changes the job even when the tooling looks similar.
Serving economics. Candidate depth, reranking, cache behavior, and hot index footprint decide what the system has to keep ready at serving time. Two stacks can return similar results and still have very different cost curves because one needs more state, candidates, or reranking capacity on the hot path.
Product contract. Stable ranking, filtering, paging, counts, access control, and explainability all increase the burden on the result.
Many systems operate under real pressure and still remain coherent. A stack can support real traffic, updates, filters, and reranking while remaining understandable to the team running it.
Strain begins when that stops being true often enough that the team notices a change in posture:
- more exceptions
- wider candidate windows
- more query-type caveats
- more cross-layer explanations
- results that remain acceptable but are no longer trusted instinctively
The stack may still look fine in a demo. It may still pass a narrow benchmark. It may still feel good enough on common cases.
The shift becomes visible when preserving stable behavior starts consuming more of the team’s attention.
Healthy regime
A healthy search stack is still bounded, predictable, and locally explainable under the retrieval job it currently carries.
Bounded means the active retrieval scope is controlled enough that the candidate set is usually sensible without heroic compensation. The stored collection may be large, but the live slice for a request is still narrow enough for filtering and ranking to work with.
Predictable means query classes behave consistently enough that the team can reason about changes before shipping them. Known-item lookup, broad discovery, filtered retrieval, and scoped similarity may behave differently, but those differences are understood.
Locally explainable means one bad result can usually be understood in one or two places, not four or five. The issue may sit in retrieval, metadata, filtering, or ranking, but the team does not have to reconstruct the whole request path every time a result looks wrong.
In this regime, candidate depth is usually stable and proportionate to the task. Filters mostly narrow the result rather than unexpectedly changing what survives. The reranker improves quality but is not carrying the system. Query classes are still broadly predictable.
Take a bounded document-search workload in construction or engineering: one project workspace, domain experts, and queries like latest approved basement mechanical plan or current fire-door schedule for phase 2. The corpus may be large overall, but the live retrieval scope is narrow enough that a relatively simple stack can stay healthy for a long time.
That kind of system still has hard cases. The retrieval job is narrow, the scope is clear, and the user often knows roughly what they are looking for. One coherent result is still relatively easy to preserve. This is why some simple stacks go surprisingly far.
Straining regime
The straining regime starts when the stack still works, but coherence gets harder to preserve. What changes is the amount of compensation needed to keep behavior stable.
The team starts widening candidate windows, adding query-specific exceptions, and preserving behavior case by case instead of trusting the stack to hold shape on its own. It explains more often and trusts less instinctively. Filters start changing whether the right candidates show up at all. Candidate depth keeps creeping upward. Query classes behave more differently than expected. Explanation and debugging cross more layers. More time goes into preserving behavior than improving the system.
When a relevance team spends more effort preserving existing behavior than making the system better, something has changed.
Broader product-shaped workloads tend to reach this regime earlier. Multi-tenant retrieval, large catalog search, cross-workspace search, policy-constrained enterprise search, and mixed discovery-plus-lookup workloads all increase the number of conditions the result has to satisfy at once.
The broad feature set may look similar to the bounded document-search case. The storage layer may look similar. The retrieval building blocks may even look similar. The operating pressure is not.
A broader system has to preserve coherence across more query classes, filters, scope boundaries, and product expectations. That is where a seemingly healthy stack starts feeling heavier every month.
A common pattern is a search stack that still looks perfectly fine on head queries and aggregate metrics, while the team quietly keeps widening candidate windows for filtered or scoped cases, adding query-specific exceptions, and spending more time explaining regressions that cross retrieval, metadata, and ranking layers.
No single change looks unreasonable. Each fix feels like a reasonable accommodation. The strain only becomes visible in the slow accumulation: more exceptions, wider windows, longer explanations, more reranking or cache pressure, and a growing sense that the system no longer holds shape without constant intervention.
What early strain actually looks like
The signs of early strain are concrete, but recurrence matters more than any single case.
Filter shift
One extra filter removes the right item entirely. The result count changes, which is expected, but the identity of the surviving results changes more than the team expected. The list is not just narrower. It is different in a way that changes the user outcome.
Filters can expose:
- stale metadata
- bad state transitions
- permissions bugs
- indexing mismatches
When the same pattern keeps returning across valid query classes, filters are deciding candidate survival instead of simply narrowing a sensible result set.
Candidate creep
The team increases K from 100 to 500 and quality improves more than expected. Some workloads genuinely need a deeper window, and this can be a valid tuning choice. It becomes a strain signal when widening the window turns into the default answer to quality complaints, especially when the latency and cost increase are easier to observe than the boundary of the gain.
At that point, the earlier stages are preserving less of the right candidate set than the team needs. Candidate depth is not only a quality signal anymore; it changes the serving economics of the path: more candidates to retrieve, score, rerank, cache, and keep within the same latency budget.
Scope drift
A result looks relevant but belongs to the wrong tenant, version, catalog, permission state, approval state, or policy state. It is textually plausible and still unusable.
This crack matters because it often looks fine until a domain expert rejects it immediately.
Sometimes the cause is local:
- wrong metadata
- stale workflow state
- incomplete synchronization
- bad partitioning
When text plausibility repeatedly outruns scope correctness, the stack is no longer preserving enough of the contract early enough.
Long-tail wobble
Head queries stay healthy while broader or less common workflows become less predictable. The common cases still look fine, but confidence drops once the query class moves away from the center.
This is how strain can stay hidden behind healthy aggregate metrics. Demos still work. Aggregate dashboards still look acceptable. The pain shows up in legitimate but less common workflows that matter to expert users.
One isolated workflow can still be weak.
When several retrieval jobs share one path but stop failing in the same way, the strain is broader than that one workflow.
Reranker rescue
The reranker is no longer just improving the ordering of good candidates. It is rescuing weak first-stage behavior.
That is not automatically a problem; a reranker is supposed to improve quality. The signal changes when more and more quality preservation moves downstream because the earlier retrieval path is no longer trustworthy enough. At that point, the reranker is not just improving relevance. It is stabilizing a strained system.
Layered debugging
One bad result now takes several layers to explain. The explanation may cross retrieval, filtering, ranking, metadata, permissions, and application logic before the team can say why the result appeared or disappeared.
A one-off cross-layer bug is still a bug.
Recurring layered debugging means the cracks are no longer local enough to fix and forget. A retrieval problem can look like filtering, a scope problem can look like ranking, and a downstream correction can make an upstream weakness look acceptable. The team is spending more energy on reconstruction than on improvement.
Healthy versus straining
A compact way to see the shift:
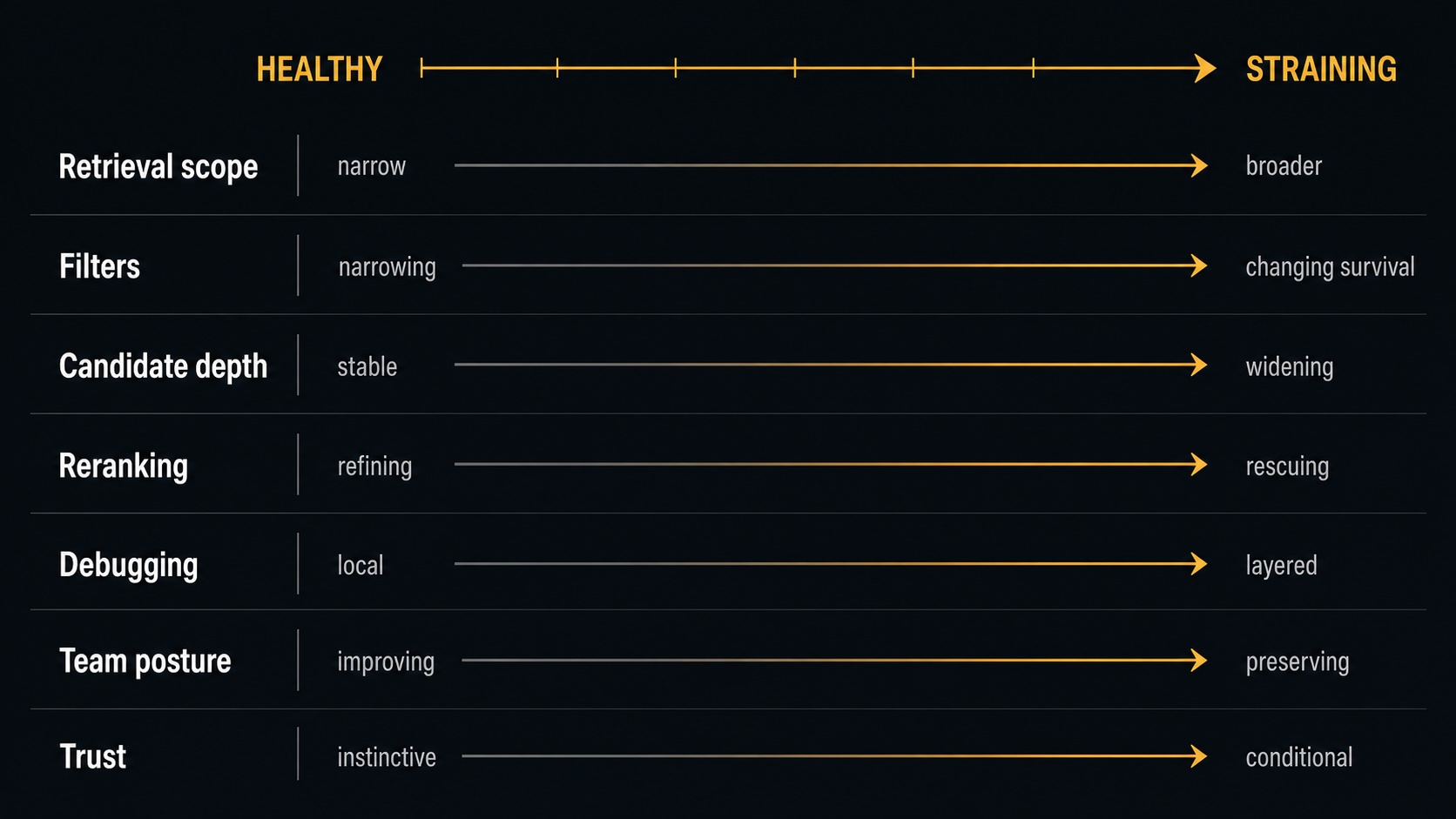
The practical distinction
Healthy systems can still have weak queries, bad metadata, or workflows that need a deeper candidate window. One crack on its own does not usually change the architecture discussion.
Many systems operate in a healthy regime for a long time. Staying put is often correct when the current stack is well understood, operationally stable, and aligned with the product contract.
The answer starts to change when the same patterns become routine: filters change candidate survival, results drift across scope, long-tail inconsistency grows, reranker rescue becomes normal, explanations cross layers, and more effort goes into preserving behavior than improving it.
That is still not the same as a migration argument. It means the operating regime has changed. The stack is carrying a broader retrieval burden, and keeping one coherent result is becoming more expensive.
Teams usually pay that cost through more exceptions, wider candidate windows, cross-layer debugging, downstream compensation, reranker load, cache pressure, and less confidence that the system will hold shape without constant intervention. The cost is easy to postpone for a while. It is harder to unwind later.
Why this matters
Most teams wait until the failure is visible: latency spikes, result quality breaks, or a product incident forces the issue. By then, the system has usually accumulated workarounds, exceptions, wider candidate windows, and cross-layer debugging habits that are harder to unwind than any single bad result.
The stack still works, but the cracks have started to recur. Local fixes are still possible, but the distinction becomes more important: is this still a local failure, or is the system entering a straining regime?
A healthy stack can have bugs. A straining stack has patterns. When the same cracks keep returning across filters, scope, candidate depth, reranking, and debugging, the problem is no longer just that one result was bad. Keeping one coherent result is becoming more expensive.
The next question is whether that cost still belongs to local cleanup and tuning work, or whether tuning has stopped compounding.
This is one reason we describe production AI systems as depending on a Retrieval Foundation.