
A search stack can still work while each iteration takes more effort to produce a meaningful gain.
Consider a marketplace search stack originally built for a narrower job: lexical retrieval, fast ranking, basic filters, and limited business controls.
That design can hold for years. Then the retrieval burden expands. Inventory changes faster. Sponsored placement grows. Region, availability, seller quality, policy rules, freshness, and personalization all begin shaping the same page.
A query like waterproof hiking shoes size 11 under 150 now carries lexical constraints, inventory state, price filters, sponsored placement, policy rules, and ranking consistency requirements at once.
Commerce makes the pattern visible, but the shape is broader: enterprise permissions, media rights, support entitlements, freshness, policy, and personalization create the same pressure. More systems start shaping the same result.
Earlier pieces covered what makes search hard and how working search stacks start to strain. This piece focuses on the next threshold: tuning has stopped compounding when each fix gives the next change more to preserve.
Rational today, expensive tomorrow
The original architecture may have been entirely rational.
A tightly controlled lexical or hybrid stack fits moderate corpus sizes, strict latency targets, dense business logic, and teams that need direct operational control. It can be cheaper, faster, and easier to reason about than a more generalized architecture.
The mismatch appears when the retrieval job changes.
Improving recall now requires deeper candidate windows. Stabilizing ranking requires more query-specific logic. Preserving business constraints requires downstream correction. Every additional rule increases the number of interactions future changes must preserve.
The cost also changes at serving time. Larger candidate windows mean more candidates to retrieve, score, rerank, cache, and explain. New semantic paths can require more index state to stay hot. More personalization or policy logic can increase the amount of state that must be joined, synchronized, or recomputed before the page can be trusted.
Mature stacks can usually be extended. What matters is what each extension does to the cost of the next gain.
A system becomes expensive when stable results require disproportionate tuning, coordination, serving cost, validation, and exception handling across layers.
Many systems that later feel limiting were well matched to their original retrieval scope, latency target, team size, serving shape, and product contract.
When tuning still works
Tuning remains effective when failures stay local.
A stale inventory state gets corrected and the workflow stabilizes. An underweighted ranking feature gets fixed without changing adjacent query classes. A deeper candidate window improves a specific broad-query class without becoming the default answer to unrelated quality problems.
One or two layers still explain most regressions. The cause is understandable before the fix and remains understandable afterward. Correcting the issue reduces future ambiguity instead of adding coordination paths, compensating logic, or query-specific exceptions.
The serving path also remains proportionate. Candidate depth stays tied to a known workload. Reranking cost is predictable. The hot working set is understood. The system does not need to keep substantially more state, candidates, or downstream correction capacity ready just to preserve the same visible behavior.
In this regime, tuning compounds. The team improves retrieval quality, ranking behavior, serving efficiency, and operational correctness.
When fixes stop staying local
The threshold is when a fix stops staying where it lands.
A retrieval change improves recall but changes filter survival. A ranking adjustment improves one query class but requires merchandising exceptions elsewhere. A deeper candidate window fixes broad queries but becomes the default answer to unrelated regressions. A reranker lift hides weaker first-stage retrieval.
The pattern matters more than any single case. The same failure shape appears across workflows. Explanations cross retrieval, filtering, ranking, inventory, policy, and merchandising. Engineers stop saying "this field is stale" or "this feature is underweighted" and start saying "this works only if the filter is not too selective" or "this result is valid but not useful."
At that point, the team is preserving behavior across a retrieval job the current architecture no longer absorbs cleanly.
The fix may still work. It just leaves the next change with more state to keep aligned, more candidates to carry, more downstream behavior to protect, or more cost to keep on the hot path.
The rising cost
The cost rises because final-result ownership has split.
This split rarely starts as a formal architecture decision. It accumulates through rational local choices: semantic retrieval is added beside the lexical stack, reranking moves outside the engine, and personalization, merchandising, or policy logic lives elsewhere. The lexical team owns the index. The data science team owns a reranker that runs outside it. The personalization team owns a service that runs after both. Nobody owns the page.
Retrieval forms the candidate pool. Filters and policy decide eligibility. A separate reranker reshapes the top candidates. Merchandising and application logic alter the visible page. Facets, counts, sorting, and paging may have been computed before the final result was modified. Each component can be locally correct while the user sees a result set assembled across systems with different visibility.
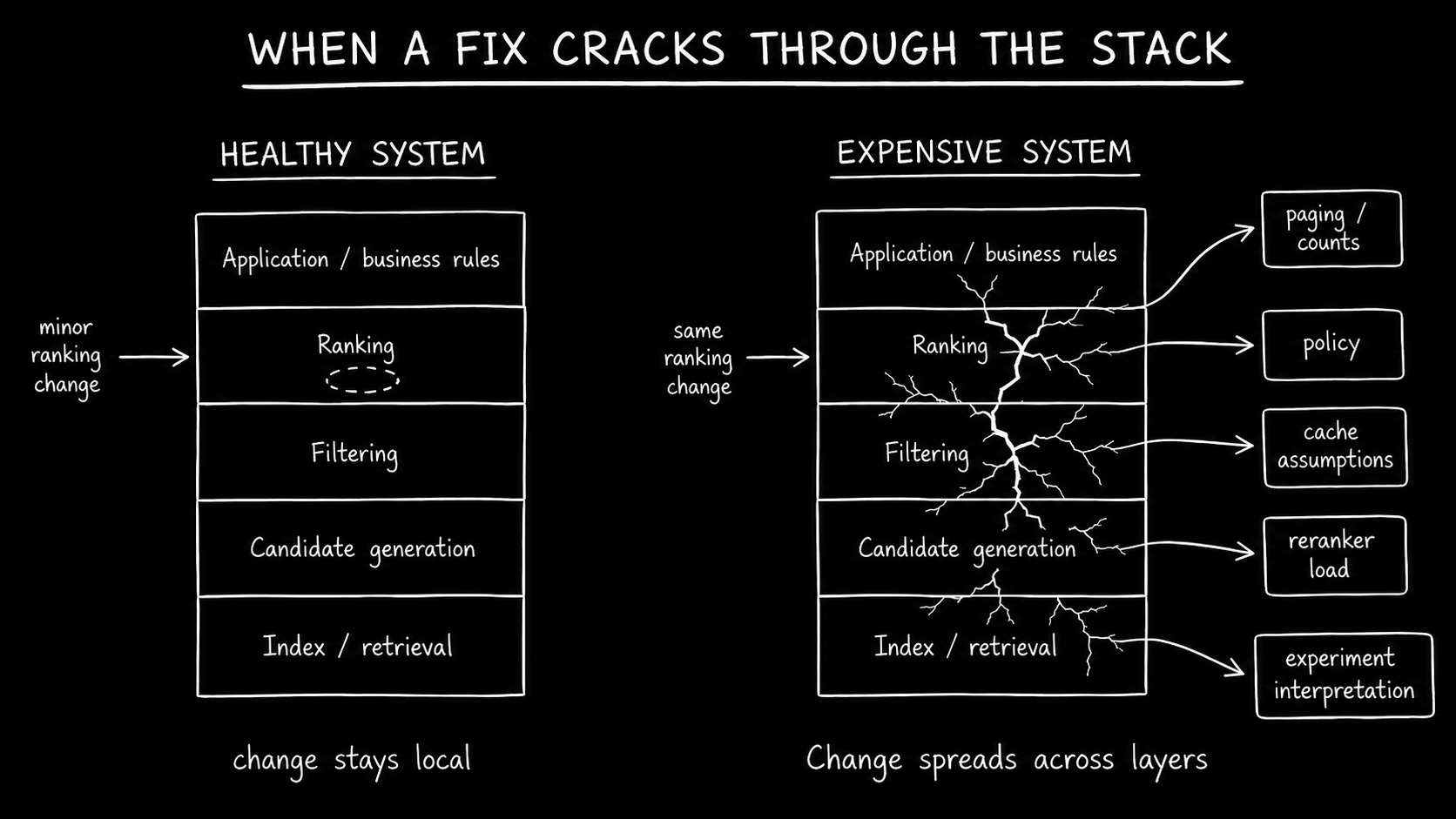
Serving cost splits too. One layer retrieves candidates, another reranks them, another applies policy or business logic, and another preserves paging, counts, or explanation. The system may still meet latency targets, but only by keeping more of the path hot, caching more aggressively, or coordinating more work across services.
Deferring architecture work converts one large cost into many smaller ones: slower ranking experiments, harder A/B interpretation, broader validation, higher serving overhead, and changes that disturb filters, counts, pagination, sponsored placement, or downstream rules.
The cost compounds when system knowledge leaves the team. New engineers inherit accumulated query rewrites, boosts, suppressions, reranker exceptions, merchandising rules, cache assumptions, and application-side corrections. The system still works, but high-impact changes feel risky because ranking behavior is no longer owned in one place.
Where the cost shows up
Engineering drag. Small improvements touch more of the stack. A ranking change now requires awareness of filters, inventory state, sponsored placement, and merchandising overrides. The signal is weak locality: the team can no longer predict where a change will stop.
Composed-result gap. Teams can be locally correct while the final result remains unstable. The lexical index, reranker, policy layer, and application each preserve their own contract. Nobody is responsible for what the user sees when all four have run.
Experiment blindness. A/B movement becomes unattributable. A metric shift cannot be traced to a single cause because retrieval, candidate survival, reranking, and downstream logic all had a hand in it. The bottleneck shifts from shipping changes to believing them.
Serving drag. The next gain requires more hot state, larger candidate windows, heavier reranking, more cache pressure, or more always-on infrastructure. The system may still be fast enough, but each improvement consumes more of the serving budget.
Opportunity drag. New product work inherits the current shape. Semantic retrieval, stronger personalization, stricter policy logic, or AI-facing retrieval become harder because each lands on an already coupled path.
In commerce, the cost shows up in conversion, add-to-cart, basket size, margin, sponsored placement yield, latency budget, and experimentation speed. Elsewhere it shows up as slower resolution, weaker compliance confidence, lower analyst trust, or more manual review. The common cost is slower learning.
Monolith versus distributed, search engine versus vector database, and legacy versus modern are packaging labels. The operating question is whether the team can change, validate, serve, and explain ranking behavior without reconstructing the whole path.
The practical test
The current architecture is still doing its job while fixes reduce ambiguity. Candidate depth stays tied to specific workloads. Experiments remain interpretable. Ranking behavior becomes more predictable after tuning. A change in one layer does not routinely require reconstruction of the whole path. Serving cost remains proportionate to the value of the change.
The architecture deserves re-evaluation when the opposite pattern becomes normal: wider candidate windows become the default response to quality problems, reranking compensates for weak candidate formation, regressions require cross-layer reconstruction, serving cost rises just to preserve current behavior, and preserving existing behavior consumes more effort than improving retrieval quality.
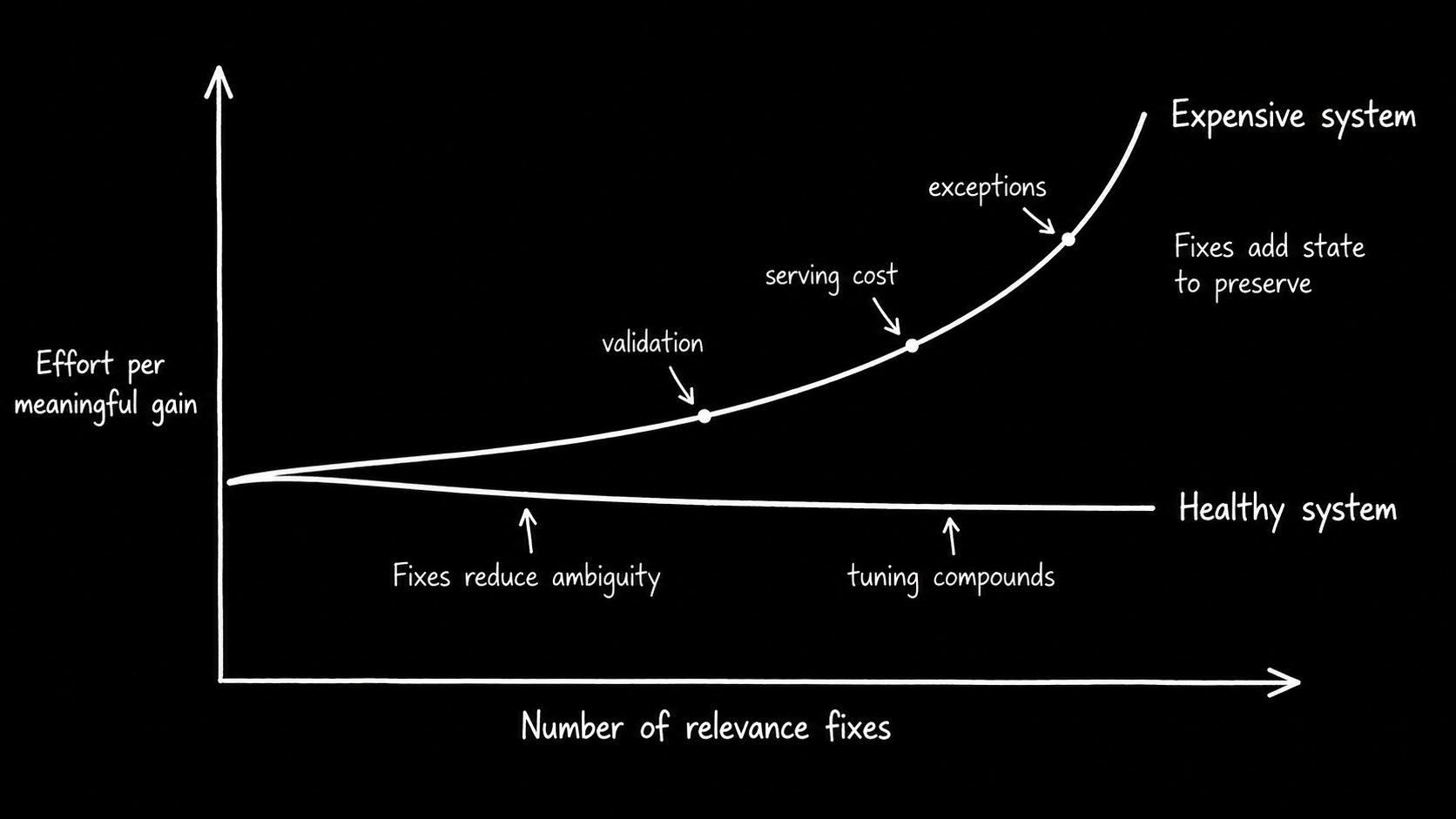
That is the decision boundary: tuning is still working when each fix makes the system easier to reason about. Tuning has stopped compounding when each fix gives the next change more to preserve.
Questions worth asking
Does a local change still stay local?
A ranking change should not routinely require filter, policy, paging, and business-rule review before anyone trusts it.
Can we explain a bad result from one place?
If one result requires reconstructing retrieval, filters, reranker inputs, rules, and application transforms, the system is no longer operating as one relevance workspace.
Are experiments teaching us, or only creating more debate?
A/B movement loses value when the team cannot tell whether a metric moved because relevance improved, candidate survival changed, serving behavior changed, or downstream logic reshaped the result.
What does each extension do to the cost of the next gain?
Mature stacks can usually be extended. The question is whether each extension lowers future ambiguity or gives the next change more to preserve.
What this does not mean
Replatforming, rewriting the stack, or abandoning mature systems under pressure is not the conclusion here.
The right response is often narrower: reduce retrieval scope, split workloads, simplify the product contract, clean up state, tune cache and candidate budgets, or make an explicit tradeoff the system currently hides.
Strong teams can keep extracting gains from a strained system long after the economics have changed. A system can remain rational for today while becoming an expensive path to the next meaningful improvement.
The cost of waiting
Once tuning stops compounding, delay accumulates debt in the search path itself. Candidate windows widen, exceptions harden, downstream correction becomes normal, ranking behavior depends on logic scattered across systems, and more of the serving path must stay ready to protect the same visible result.
The organization may be avoiding a large migration, but it is still paying. It pays through slower experiments, longer validation cycles, weaker onboarding, higher serving cost, lower confidence in local changes, and fewer high-conviction attempts to improve the business metric.
Waiting does not avoid the architecture decision. It moves the cost into every future relevance change.
This is one reason we describe production AI systems as depending on a Retrieval Foundation.